Список вызовов функций «Function List»
Одно из наиболее важных статистических окон. Здесь в табличном виде выводится статистическая информация по числу и времени работы каждой функции. Рисунок 6 демонстрирует окно с включенной сортировкой по числу вызовов каждой функции. В качестве дополнительной информации включен список формальных параметров вызовов функций. Подобную информацию можно получить только в том случае, когда тестируется модуль с отладочным кодом, к которому прилагается исходный текст.
Единицы измерения длительности работы функций могут быть следующими:
- Микросекунды;
- Миллисекунды;
- Секунды;
- Машинные циклы.
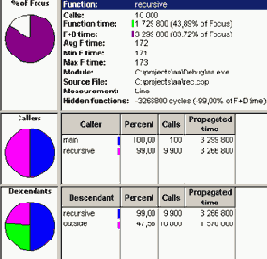
На рисунке приведены цифры соответствующие машинным циклам.

Полученная таблица вызовов анализируется тестером или разработчиком для выяснения узких мест в производительности приложения.
К сожалению, для принятия решения о производительности приложения, а точнее, производительности отдельных его функций можно принимать только рассматривая данный вопрос в комплексном разрезе. А именно, принимается во внимание и число вызовов каждой функции, и среднее время доступа к функции и общее время работы функции, и, наконец, то использовались ли при компиляции определенные специфические настройки компилятора.
Это комплексный подход, не предполагающий однозначного совета.
Сначала рассмотрим описание столбцов в появившейся таблице. Хотя многие из пунктов и являются интуитивно понятными, все же попробуем дать им короткое описание:
- Function. Наименование функции. Можно высвечивать число и тип формальных параметров вызова данной функции.
- Calls. Число вызовов. Величина абсолютная.
- Function Time. Общее время исполнения всех вызовов данной функции
- Max F Time. Максимальное время функции
- Module. Полный путь до модуля с функцией (бинарного)
- Min F Time. Минимальное время работы функции
- Source File. Полный путь до исходных текстов модуля.
По любому из предложенных полей можно провести сортировку в прямом и обратном порядке, а также наложить фильтр на определенные модули, например, для проверки только внутренних модулей или только внешних.
Выделить из списка узкую функцию трудно, поскольку для правильного расчета нужно принимать во внимание и время работы функции и число вызовов.
Причем, число вызовов не всегда может быть показателем медлительности функции (вызывается часто, а работает быстро). Трудно давать какие либо советы по оптимизации кода, тем более, что в этой редакции мы не ставили перед собой подобных целей. По теории оптимизации написаны громадные труды, к которым мы с радостью и отправляем читателей. Можно, конечно, дать общие рекомендации по улучшению производительности кода и его эффективности: Использовать конструкцию «I++» вместо «I=I+1», так как компиляторы транслируют первую конструкцию в более эффективный код. К сожалению, этот эффективность примера ограничена настройками используемого компилятора, и иногда бывает равнозначной по быстродействию; Использовать прием развертывания циклов. Такой же старый прием оптимизации работы относительно простых циклов. Эффект заключается в сокращении числа проверок условия счетчика, так при проверке выполняются очень медленные функции микропроцессора (функции перехода). То есть вместо кода: For(i=0;i<100;i++)sr=sr+1; Лучше писать: For(i=0;i<100;i+=2)
{
sr++;
sr++;
} Использовать тактику отказа от использования вычисляющих конструкций внутри простых циклов. То есть, если иметь подобный фрагмент кода: for (sr = 0; sr < 1000; sr++)
{
a[sr] = x * y;
} то его лучше преобразовать в такой: mn= x * y;
for (sr = 0; sr < 1000; sr++)
{
a[sr] = mn;
} поскольку мы избавляемся от лишней операции умножения в простом цикле; Там где возможно при работе с многомерными массивами, обращаться с ними как с одномерными. То есть, если есть необходимость в копировании или инициализации, например, двумерного массива, то вместо кода: int sr[400][400];
int j, i; for (i = 0; i < 400; i++)
for (j = 0; j < 400; j++)
sr[j][i] = 0; лучше использовать конструкцию, в которой нет вложенного цикла: int sr[400][400];
int *p = &sr[0][0]; for (int i = 0; i < 400*400; i++)
p[sr] = 0; // или *p++=0, что для большинства компиляторов одно и тоже
Также при работе с циклами выгодно использовать слияния, когда несколько коротких однотипных циклов сливаются вместе.
Подобный подход также дает прирост в производительности кода; В математических приложениях, требующих больших вычислений с плавающей точкой, или с большим количеством вызовов тригонометрических функций, удобно не производить все вычисления непосредственно, а использовать подготовленные значения в различных таблицах, обращаясь к ним как к индексам в массиве. Подход очень эффективен, но, к сожалению, как и многие эффективные подходы применим не всегда; Короткие функции в классах лучше оформлять встроенными (inline); В строковых операциях, в операциях копирования массивов лучше пользоваться не собственными функциями, а применять для этого стандартные библиотеки компилятора, так как эти функции, как правило, уже оптимизированы по быстродействию; Использовать команды SSL и MMX, поскольку в достаточно большом круге задач они способны дать ускорение работы приложений в разы. Под такие задачи попадают задачи по работе с матрицами и векторами (арифметические операции над матрицами и векторами); Использовать инструкции сдвига вместо умножений и делений там, где это позволяет делать логика программы. Например, инструкция S=S<<1 всегда эффективнее, чем S=S*2; Конечно, это далеко не полный список приемов оптимизации кода по производительности и качеству. Для этого есть масса других книг. Примеры здесь имеют чисто утилитарный подход: демонстрация возможностей Quantify в плане исследования временных характеристик кода. Используя все средства сбора и отображения, разработчик постепенно сможет использовать только эффективные конструкции, что поднимет производительность на недосягаемую ранее высоту. По любой функции можно вывести более детальный отчет (см. рисунок). Из него можно почерпнуть информацию о числе дочерних функций и то, откуда они были произведены. Следующий рисунок демонстрирует данную возможность.